由于工作需要,近期使用vLLM + Qwen3.5完成了内网AI的部署,本文为部署笔记。本教程的运行硬件为NVIDIA A100/V100 GPU,操作系统为Ubuntu 22.04 LTS版本。
和Ollama、LMStudio等个人简易运行不同,部署生产环境可用的AI模型需要多个软硬件的协同工作。本人非AI领域的专家(也非目前交火的前向部署工程师 FDE),以下软硬件链路是个人经验总结,仅供参考。
使用vLLM + Qwen3.5部署内网AI
推理引擎vLLM和开源模型Qwen 3.5选择理由:本人之前 Ollama部署 主要是测试目的,生产环境要考虑并发和吞吐,主流的推理引擎/框架有 vLLM、SGLang、TensorRT-LLM 等;vLLM社区、文档和应用都非常成熟,因此成为本人第一选择;Qwen3.5目前算是能打且有多种参数规模的开源模型(GLM、Kimi等没有单卡能运行的小参数模型),并且Hugging Face上有许多蒸馏Claude Code的Qwen3微调版本,适合资源不充分的团队使用。
1. 准备GPU驱动和CUDA Toolkit
本人手上部署AI可用的GPU硬件包括:NVIDIA A100 80G 和 NVIDIA V100 32G 两种,都是纯计算卡。要让NVIDIA能力发挥出来,首先需要安装GPU驱动和CUDA Toolkit。根据硬件条件和使用情况,本人选择了CUDA 12.9版本的CUDA Toolkit。根据 NVIDIA官网教程,安装方法如下:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb dpkg -i cuda-keyring_1.1-1_all.deb # 更新软件包信息并安装CUDA Toolkit和驱动 apt update apt install gcc-12 g++-12 apt install -y cuda-toolkit-12-9 apt install -y cuda-drivers
特别需要注意的是,Ubuntu 22.04 LTS版本系统自带的是GCC 12。GPU驱动(包含在cuda-drivers)使用的gcc 12编译,需要手动安装gcc 12才能正常将nvidia驱动模块编译到内核,否则可能会报“dpkg: error processing package nvidia-driver-xxx”的错误。
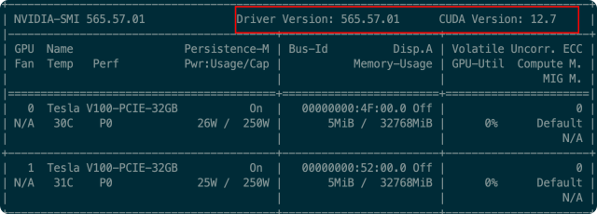
安装好驱动后需要重启系统,然后可以通过 nvidia-smi查看GPU和驱动的信息:
2. 安装推理框架vLLM
Python应该是AI的第一编程语言,因此vLLM官方推荐使用UV来管理python环境和安装vLLM:
# 安装UV curl -LsSf https://astral.sh/uv/install.sh | sh # UV激活新环境并安装vllm mkdir vllm && cd $_ uv venv --python 3.12 --seed # 本人测试3.10运行有问题,建议使用3.12版本 source .venv/bin/activate uv pip install vllm --torch-backend=cu129 # 可以使用--torch-backend=auto自动检测支持的后端
需要注意的是,对于NVIDIA V100 GPU,本人测试的最后一个能正常运行的vLLM版本是0.19.1(PyTorch 2.11版本不再支持CC 70的V100)。如果你在使用这张卡,需要手动指定 vLLM 版本(不要高于0.19.1):
uv pip install vllm=0.19.1 --torch-backend=cu129
安装Hugging Face CLI和下载模型
GPU驱动已经准备好,推理引擎也到位,接下来需要下载模型文件。推荐使用Hugging Face CLI工具和国内镜像下载模型文件:
pip install -U huggingface_hub HF_ENDPOINT=https://hf-mirror.com hf download Qwen/Qwen3.5-27B-FP8 \ --local-dir Qwen3.5-27B-FP8
根据本人测试和网上反馈,27B的稠密模型比35B的MOE稀疏模型表现更好,因此使用的27B稠密模型,模型大小约30G,可以在一张A100 80G的显卡上稳定运行。
运行模型
GPU、推理引擎、模型已经到位,接下来是运行模型:
export OMP_NUM_THREADS=4 # 初次启动可设置大一些,后续可设置为1
export PORT=8001
export MODEL=Qwen3.5-27B-FP8
export VLLM_MARLIN_USE_ATOMIC_ADD=1
export CUDA_VISIBLE_DEVICES="0" # 只使用第一张显卡部署
export VLLM_SLEEP_WHEN_IDLE=1
vllm serve ./$MODEL \
--served-model-name "$MODEL" \
--mamba-cache-model align \
--gpu-memory-utilization 0.9 \
--max-model-len 262656 \
--max-num-seqs 32 \
--max-num-batched-tokens 32768 \
--enable-prefix-caching \
--enable-chunked-prefill \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--language-model-only \
--port $PORT \
--override-generation-config '{"temperature": 0.6, "top_p": 0.95, "top_k": 20, "min_p": 0.00, "max_tokens": 65536, "presence_penalty": 0.0, "repetition_penalty": 1.0}' \
--speculative-config '{"method": "mtp", "num_speculative_tokens": 2}' \
--dtype float16 \
--kv-cache-dtype fp8 \
--block-size 32 \
--load-format safetensors
这里设置上下文长度(–max-model-len)为256K(编程场景建议至少128K),并且只能输入文本(–language-model-only),以及配置了编程相关的配置(–override-generation-config)。上面的许多参数可以根据业务场景和经验进行微调。
vLLM首次启动会调用ptxas编译ptx指令为机器显卡能直接运行的SASS,可能会耗时较长。启动成功后可以通过curl查看vLLM运行的模型信息:
curl http://localhost:8001/v1/models
模型正常运行后,可以通过 vLLM 自带的 bench 指令测试部署模型的性能:
vllm bench serve \ --backend openai-chat \ --endpoint /v1/chat/completions \ --model Qwen3.5-27B-FP8 \ --dataset-name random \ --random-input-len 2048 \ --random-output-len 512 \ --num-prompts 100 \ --request-rate 20
Nginx负载均衡
如果有多张显卡(更改CUDA_VISIBLE_DEVICES环境变量),可以监听不同的端口(更改启动时候的–port参数)并使用Nginx做负载均衡:
apt install nginx
添加Nginx反代和负载均衡配置:
upstream vllm_backend {
server 127.0.0.1:8001;
server 127.0.0.1:8002;
# 长连接池(关键!)
keepalive 32;
# 负载均衡策略
least_conn; # 最少连接优先,比轮询更适合 LLM
}
server {
listen 8000;
server_name localhost;
# 请求体大小限制
client_max_body_size 100M;
# 超时配置(关键!LLM 需要更长时间)
proxy_connect_timeout 300s;
proxy_send_timeout 300s;
proxy_read_timeout 300s;
location / {
proxy_pass http://vllm_backend;
# HTTP/1.1 支持(keepalive 必需)
proxy_http_version 1.1;
# 清除 Connection 头(让 keepalive 生效)
proxy_set_header Connection "";
# 传递必要头部
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 禁用缓冲(流式响应关键!)
proxy_buffering off;
proxy_cache off;
# 流式优化
proxy_request_buffering off;
# 重试配置(后端失败时自动重试)
proxy_next_upstream error timeout http_502 http_503 http_504;
proxy_next_upstream_tries 2;
proxy_next_upstream_timeout 10s;
}
}
至此,本地运行的AI模型已经准备到位,接下来可以在内网环境下使用 CLINE / OpenCode 等工具来使用AI Agent模式编程了。
备注
1. 目前Qwen3系列的最新模型是 Qwen3.6;
2. CUDA Toolkit 12.8开始不再原生支持V100显卡,由于向后兼容性驱动和CUDA toolkit 12.x系列都能正常运行,CUDA 13.x就未必了,这也是本文使用12.9的原因;
3. vLLM 支持张量并行(tensor-parallel)和数据并行(data parallel)两种模式来使用多张GPU卡,本文使用Nginx反代是为了保持系统鲁棒;
4. 有了Hugging Face CLI 和 vLLM,建议多下载一些模型测试,选择最适合自己的模型。
参考
发表回复