自春节以来,DeepSeek爆火,以至于官网都经常出现“服务器繁忙请稍后重试”,并且一度关闭了API注册和充值入口。好消息是可以本地部署使用,数据安全性和隐私更有保障。本文简要介绍使用Ollama和Open-WebUI本地部署DeepSeek。
1. 安装Ollama和运行模型
Ollama 是一个 开源免费 的 大语言模型服务工具,能帮助用户快速在本地部署和运行大语言模型。它简单易用,支持多平台,功能齐全,更重要的是 提供丰富的模型供用户一键下载和运行。目前爆火的 DeepSeek系列模型,包括DeepSeek R1满血版、DeepSeek R1蒸馏版以及DeepSeek V3版本,都可以一条命令启动和运行。
安装Ollama很简单,一条命令就可以搞定:
curl -fsSL https://ollama.com/install.sh | sh
但是,由于国内的网络环境你懂的,脚本中的 Ollama 安装包无法下载(比如本人所在网络就不行)。此时你需要先下载 install.sh 脚本,然后修改脚本使用代理进行下载。这时候之前部署的 PHP开发的Github文件下载加速项目 就派上用场了:搜索脚本中的 https,前面加上 https://gh.2i.gs/,就能正常下载和使用了。
安装好 Ollama 后,接着就可以运行 DeepSeek 的大模型了。网上给出的 DeepSeek- R1本地部署的硬件要求如下图,自己可根据硬件情况选择相应模型:
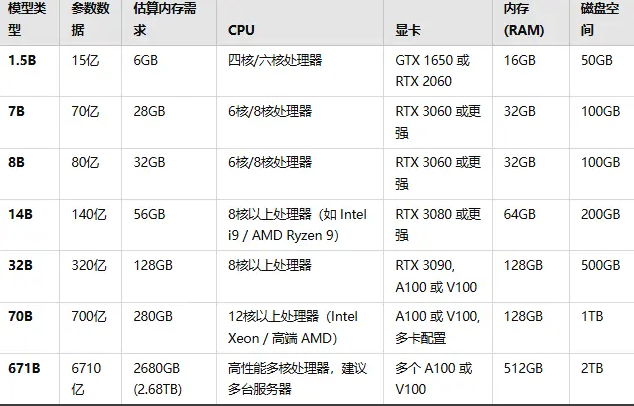
本人使用的服务器有4张NVIDIA V100显卡和500G内存,理论上来说部署DeepSeek R1满血版是没有问题的。但是考虑到硬盘和其他服务使用,选择了DeepSeek R1 70B版本。启动和运行命令是:
ollama run deepseek-r1:70b
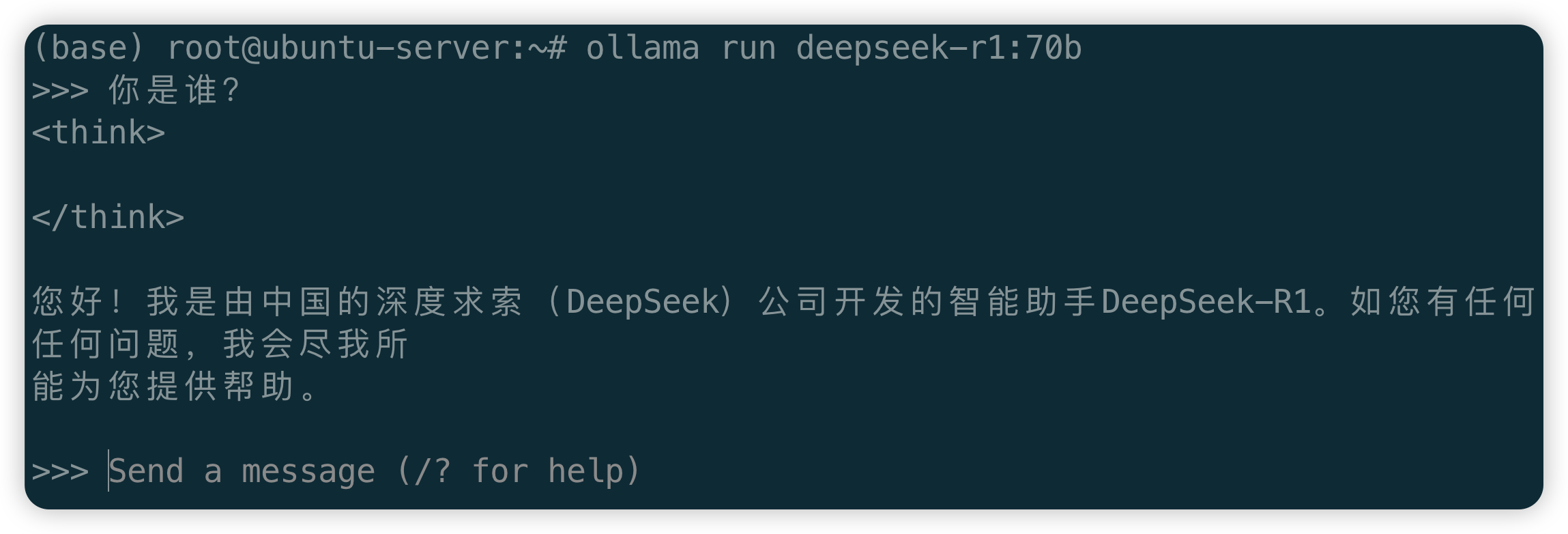
初次运行会下载模型文件,启动后会出现提示符,可直接输入问题进行聊天互动:
此时打开浏览器访问 http://localhost:11434,会看到页面上显示 “Ollama is running”,说明已经成功部署好了Ollama。
如果你是本地部署,此时已经使用 http://localhost:11434 和模型id(例如 deepseek-r1:70b)这两个信息在 Contine、CLINE、Cherry Studio 等工具中使用。例如Visual Studio Code(VS Code)中的Contine插件配置文件示例为:
{
"models": [
{
"apiBase": "http://127.0.0.1:11434/",
"model": "deepseek-r1:70b",
"provider": "ollama",
"title": "ollama"
}
],
... other configsCLINE插件配置截图:
如果你希望远程访问,则还需要进一步进行设置。
2. Ollama运行高级设置
1. 除了DeepSeek系列,Ollama支持更多模型,具体可以到官网搜索: https://ollama.com/search,网页上会介绍模型的详细情况和运行命令。
2. Ollama默认监听 127.0.0.1,因此只能本机使用。如果你希望让其它机器或者 docker 容器连接,则需要让其监听其它ip地址的流量,例如允许所有ip的连接:0.0.0.0。一种修改方法是修改启动脚本,一般路径是 /etc/systemd/system/ollama.service,添加 Environment=”OLLAMA_HOST=0.0.0.0:11434″ 一行,修改后的文件类似于:
[Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/local/bin/ollama serve User=ollama Group=ollama Restart=always RestartSec=3 Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin:/usr/local/cuda-12.6/bin" Environment="OLLAMA_HOST=0.0.0.0:11434" Environment="CUDA_VISIBLE_DEVICES=0,1,2,3" [Install] WantedBy=default.target
3. 默认Ollama会使用所有可用的GPU,如果你希望只使用某些GPU,可以通过环境变量设置。上面的配置文件显式指定了使用编号为0,1,2,3的GPU:Environment="CUDA_VISIBLE_DEVICES=0,1,2,3"。
4. 如果你的服务器有公网ip并且修改了Ollama监听 0.0.0.0,请务必设置网络访问授权!Ollama默认没有访问授权,因此所有能连接到服务器和端口的人都可以使用你部署的模型!为了安全以及避免资源被滥用,请严格限制访问权限!
3. 搭建Open WebUI使用网页聊天
Open WebUI是一个自托管的人工智能平台,支持各种大语言模型(LLM),自然是支持上文说的Ollama。通过Open WebUI,我们可以搭建一个类似于ChatGPT的网站聊天,支持多人、多模型的使用。
通过 docker 的方式搭建Open WebUI非常简单,一条命令搞定:
docker run -d -p 8080:8080 --add-host=host.docker.internal:host-gateway \ -v open-webui:/app/backend/data --name open-webui --restart always \ ghcr.io/open-webui/open-webui:main
上述命令中,你需要修改的便是映射的端口(比如我使用8080)和挂载文件夹(命令中是open-webui)。
也可以通过 python 启动:
#官方推荐python 3.11,但是本人测试python 3.12也正常没问题。如果你需要python 3.11,建议使用conda管理和安装:
# 下载和安装miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh bash ~/Miniconda3-latest-Linux-x86_64.sh conda init# 创建python 3.11环境
conda create -n open-webui python=3.11.0
首先 pip 安装open-webui: pip install open-webui
然后开启open-webui服务:open-webui serve --port 8080,此时会输出类似如下界面:

需要注意的是,无论是 docker 还是 pip 方式,open-webui第一次运行的时候都巨慢!此时你打开浏览器访问 http://localhost:8080 (8080改成你的端口号)会得到一片空白!根据日志信息,第一次启动耗时将近4分钟,这是因为首次会下载一些东西,但是国内的网络你懂的。
Open WebUI启动之后,会出现管理员注册页面。输入你的邮箱和密码,这就创建了管理员账号。Open WebUI管理员账号创建完了后,你可能接着又迎来一次空白页面,让人很懵逼!这是因为默认开启了OpenAI的API,尝试会去连接。等几分钟后才会出现预期的聊天界面。
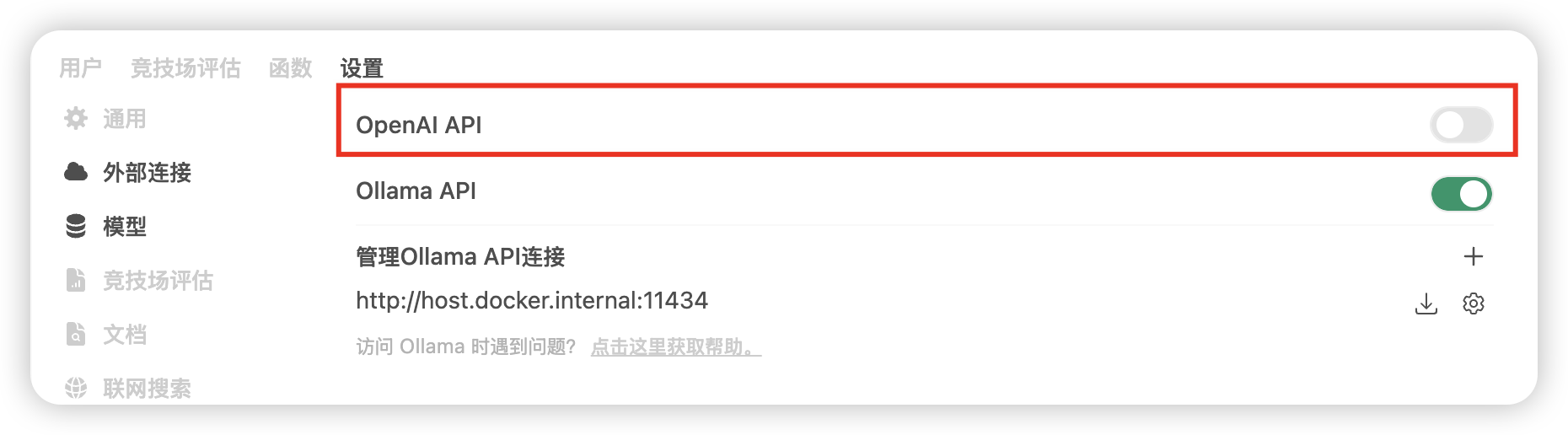
如果你的服务器在国内,建议你第一时间进入管理后台,把OpenAI的API关闭,否则经常会遇到页面空白的情况:
接着,你就可以正常的在Open WebUI上和部署的各个模型聊天对话了:

如果你在内网搭建让其他人也能使用,则可以开启用户注册功能。如果不想麻烦的一个个激活,可以设置默认用户角色为用户:

最后就是默认的模型都是私有的,也就是管理员可以用。要模型可以给其他人用,在模型标签页点击要放开访问的模型,将可见性改成“Public”即可:
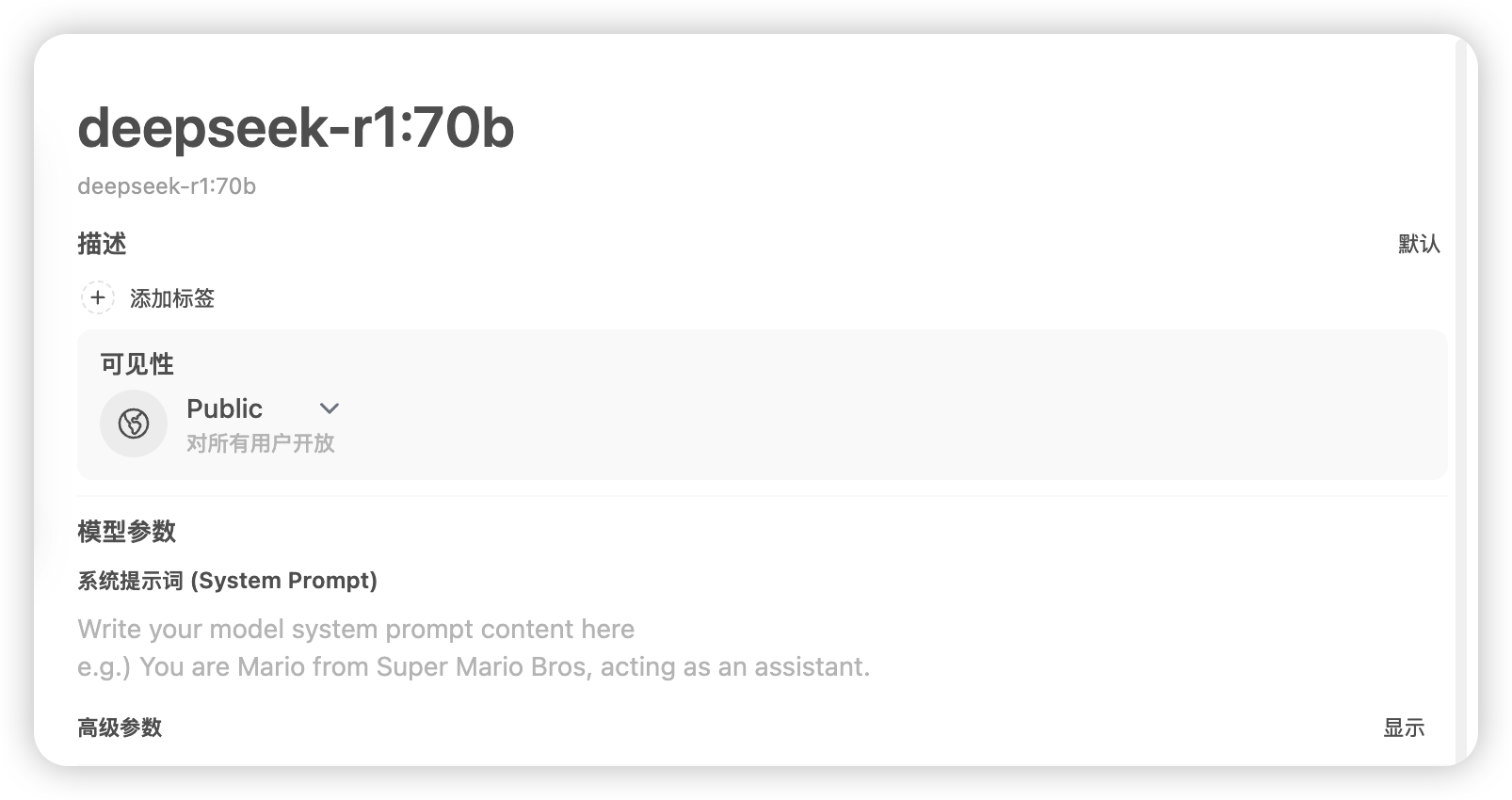
由于搭建DeepSeek是为了数据隐私和安全,因此没有接入联网搜索功能。如果需要联网搜索,请参考官网教程。但是对于支持的供应商,我对国内网络能否正常使用持怀疑态度。
总结
本文简要介绍了使用Ollama部署和使用deepseek r1及其他模型,同时给出使用Open WebUI搭建又用户管理功能聊天网站的教程。对于搭建和部署过程中的一些坑,本文根据经验解释了原因和解决办法,希望能帮到遇到类似问题的网友。





gemini 2.5 pro免费又强大,没必要再自己折腾了
又过去几个月,出了很多新的强大的模型,自用不必再折腾自己部署了
部署半天还是发现原版好用
自己部署的提示词,参数等一般没有官方优化的好,不连外网的部署才比较有意义
建议你试一下部署r1-1776模型,它是由Perplexity公司基于deepseek-r1再进行后训练的,把deepseek-r1蒸漏OpenAI时过滤屏蔽掉的内容都补全了
效果更好吗?